






标题:实时数据库表的构建:技术解析与最佳实践
<h2>引言</h2>
<p>随着大数据时代的到来,实时数据处理的需求日益增长。实时数据库表能够提供即时的数据查询和分析能力,对于需要快速响应的业务场景至关重要。本文将深入探讨如何建立实时数据库表,包括技术原理、构建步骤以及最佳实践。</p>
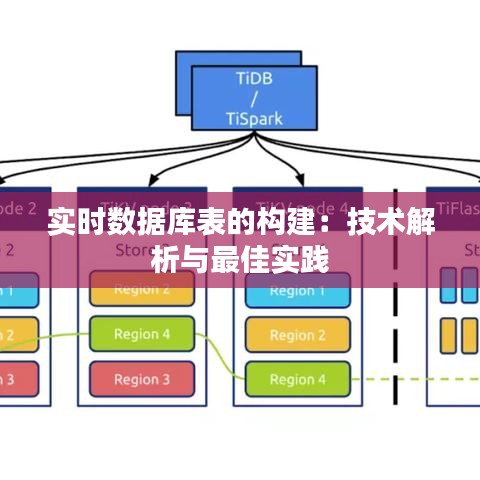
<h2>实时数据库概述</h2>
<p>实时数据库是一种能够快速处理和响应数据变化的数据库系统。它与传统数据库的主要区别在于对数据变化的高效捕捉和即时处理能力。实时数据库通常用于需要实时监控、分析和决策的场景,如金融交易、在线游戏、物联网等。</p>
<p>实时数据库的关键特性包括:</p>
<ul>
<li>低延迟:数据处理的延迟极低,通常在毫秒级别。</li>
<li>高吞吐量:能够处理大量的数据写入和查询请求。</li>
<li>可扩展性:能够根据需求动态调整资源,以应对数据量的增长。</li>
</ul>
<h2>选择合适的实时数据库技术</h2>
<p>构建实时数据库表的第一步是选择合适的数据库技术。以下是一些流行的实时数据库技术:</p>
<ul>
<li>Apache Kafka:一个分布式流处理平台,适用于高吞吐量的数据流处理。</li>
<li>Apache Flink:一个流处理框架,提供实时数据处理和分析能力。</li>
<li>Amazon Kinesis:一个可扩展的流处理服务,适用于处理实时数据流。</li>
<li>Redis:一个高性能的键值存储系统,适用于快速数据检索和实时数据更新。</li>
</ul>
<p>选择时需要考虑以下因素:</p>
<ul>
<li>数据量:选择能够处理预期数据量的技术。</li>
<li>延迟要求:根据业务需求选择合适的延迟阈值。</li>
<li>可扩展性:考虑技术是否支持水平扩展。</li>
<li>社区支持:选择有良好社区支持和文档的技术。</li>
</ul>
<h2>实时数据库表的构建步骤</h2>
<p>以下是构建实时数据库表的步骤:</p>
<ol>
<li><strong>需求分析</strong>:明确业务需求,确定数据模型、数据类型和索引策略。</li>
<li><strong>设计数据模型</strong>:根据需求设计合适的数据模型,包括表结构、字段类型和关系。</li>
<li><strong>选择存储引擎</strong>:根据数据特点和性能要求选择合适的存储引擎,如InnoDB、SSD等。</li>
<li><strong>配置数据库参数</strong>:调整数据库参数以优化性能,如缓冲池大小、连接数等。</li>
<li><strong>数据导入</strong>:将历史数据导入到实时数据库表中。</li>
<li><strong>数据同步</strong>:建立数据同步机制,确保实时数据能够及时更新到数据库中。</li>
<li><strong>监控与优化</strong>:持续监控数据库性能,根据监控结果进行优化。</li>
</ol>
<h2>最佳实践</h2>
<p>以下是构建实时数据库表的一些最佳实践:</p>
<ul>
<li><strong>使用分区表</strong>:将数据分区可以提升查询性能和可管理性。</li>
<li><strong>建立索引</strong>:合理使用索引可以加速数据检索。</li>
<li><strong>异步写入</strong>:使用异步写入可以减轻数据库压力,提高系统吞吐量。</li>
<li><strong>数据清洗</strong>:确保数据质量,避免错误数据影响实时分析。</li>
<li><strong>备份与恢复</strong>:定期备份数据,确保数据安全。</li>
</ul>
<h2>结论</h2>
<p>实时数据库表的构建是一个复杂的过程,需要综合考虑技术选型、数据模型设计、性能优化等多个方面。通过遵循上述步骤和最佳实践,可以构建出高效、可靠的实时数据库表,满足现代业务对实时数据处理的需求。</p>转载请注明来自武汉雷电雨防雷工程有限公司,本文标题:《实时数据库表的构建:技术解析与最佳实践》
百度分享代码,如果开启HTTPS请参考李洋个人博客






 鄂ICP备19026574号-1
鄂ICP备19026574号-1